Operator APIs | Lists
Using the new NetRefer Identity to request a JWT
OAuth 2.0 is required to get access to the NetRefer Data Ingestion API.
To authenticate within NetRefer and call the Data APIs, developers must request JWT. Copy this url: https://netreferb2c{env}.b2clogin.com/netreferb2c{env}.onmicrosoft.com/b2c_1_si_pwd/oauth2/v2.0/token to make a request.
The body of the post request should contain the following parameters:
client_id: "This will be provided by NetRefer"
username: "The user name/email of your M2M user account, provided by NetRefer of through the platform portal"
password: "The password of your M2M user account, provided by NetRefer of through the platform portal"
grant_type: "password"
scope: "openid offline_access https://netreferb2c{env}.onmicrosoft.com/NetRefer.Api.Lists/Lists.Read.All"
Once all the requirements are met, execute an HTTP POST call to "Access Token URL" to get the JWT.
API Lists Authentication
NetRefer’s API lists allow users to query, automate, and extract specific information from their platform.
To access the APIs, clients should have an appropriate account registered with NetRefer. This account can be obtained directly from NetRefer by contacting our support team or creating it through our new self-service platform.
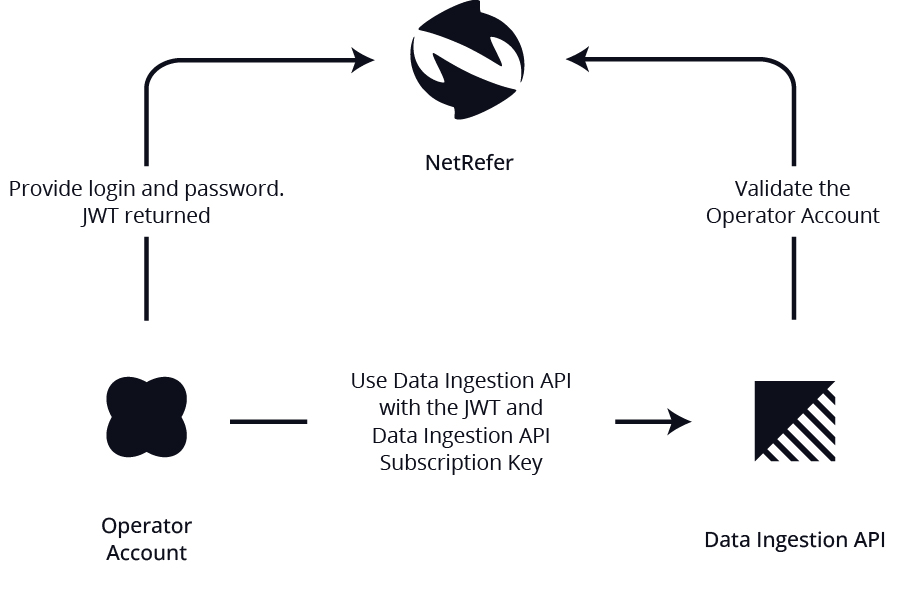
Making the call to API Lists
Once authenticated, the following 2 headers are expected every time a call is made:
Ocp-Apim-Subscription-Key: will be provided by NetRefer of through the platform portal
Authorization: Bearer {{JWT token from previous call}}
A full example of the Data Ingestion API call is illustrated in the diagram below.
The result would be a JSON Array with any found results.
GraphQL
The API lists work through GraphQL, an open-source data query language. It provides a more efficient, powerful, and flexible alternative to REST for serving data over HTTP. Here are some key features and concepts of GraphQL:
Key Features of GraphQL
Flexible Querying:
Clients can request and specify the exact data they need without having to extract other unrequested data. This avoids over-fetching and under-fetching issues common in REST APIs.
Single Endpoint:
Unlike REST, where multiple endpoints are often required, GraphQL APIs typically use a single endpoint to handle all types of requests.
Strongly Typed Schema:
GraphQL uses a schema to define the types of data that can be queried and the relationships between them. This schema is strongly typed, which provides clear expectations and allows for powerful developer tools.
Real-time Capabilities:
Through subscriptions, GraphQL can support real-time updates, allowing clients to receive data changes as they happen.
Building the Query
The query is structured in 2 main parts: the top part is the declaration of the parent attributes, mainly operatorID and correlationID. These attributes are optional, but they can be useful to the caller especially if they pull data from multiple operators simultaneously, or encounter errors during the pulls. The second part would be the actual dataset deceleration.
In the above case, we query the Marketing source data set. The data set query is split into 2 parts, the filtering part and the result set format part.
The data filtering part of the query can be seen below.
In this section, we declare the number of items to skip (mainly used to page through the data), the number of records to take at one go, and the where clause. Within the where clause we can have from simple to complex clauses. In the example above, we do the following clauses:
We check for the marketing sources where they were lastUpdated greater than 2024-01-01 and check where the marketingSourceURLURI contains casino or marketingSourceURLURI contains red or marketingSourceURLURI contains bet.
A simpler example would be where: { affiliateId: { eq: 1900 }, lastUpdated: { ngt: "2024-01-01"} }.
In this case, we search in marketingSource where affiliateId is equal to 1900 and lastUpdated is not greater than 2024-01-01.
For the complete guide on how to build the filter, you can refer to this link Filtering - Hot Chocolate - ChilliCream GraphQL Platform
The last part of the request is the dataset declaration. This is where the caller specifies which attributes to call. In the example above the following attributes are being queried. The caller might decide to include more or less attributes (depending on the availability).
The final output will be a Json object (in the example below we take 5 records). As we can see, the output mimics the query where operatorID and correlationID are at the top. Then, when we get to the data set marketingSource, we can also see the data set information (based on the Query) i.e., total count and page info. Finally, we can see an array of data with the items of the result.
Available Lists
GraphQL is an API query language that allows the API user to define the structure of the data returned. Due to this, the first important piece before querying the endpoint is to gain access to the platform by getting a NetRefer account (use an M2M account for automation and machine-to-machine connections) and issuing an API key to that account.
Once the user has access to the API, they can access one of the following datasets:
Kindly note that for the Affiliate Earned Rewards and Customer Rewards the data available is for the last 3 calendar months, should you require access to older data kindly use the PMP Reports or contact NetRefer directly.
